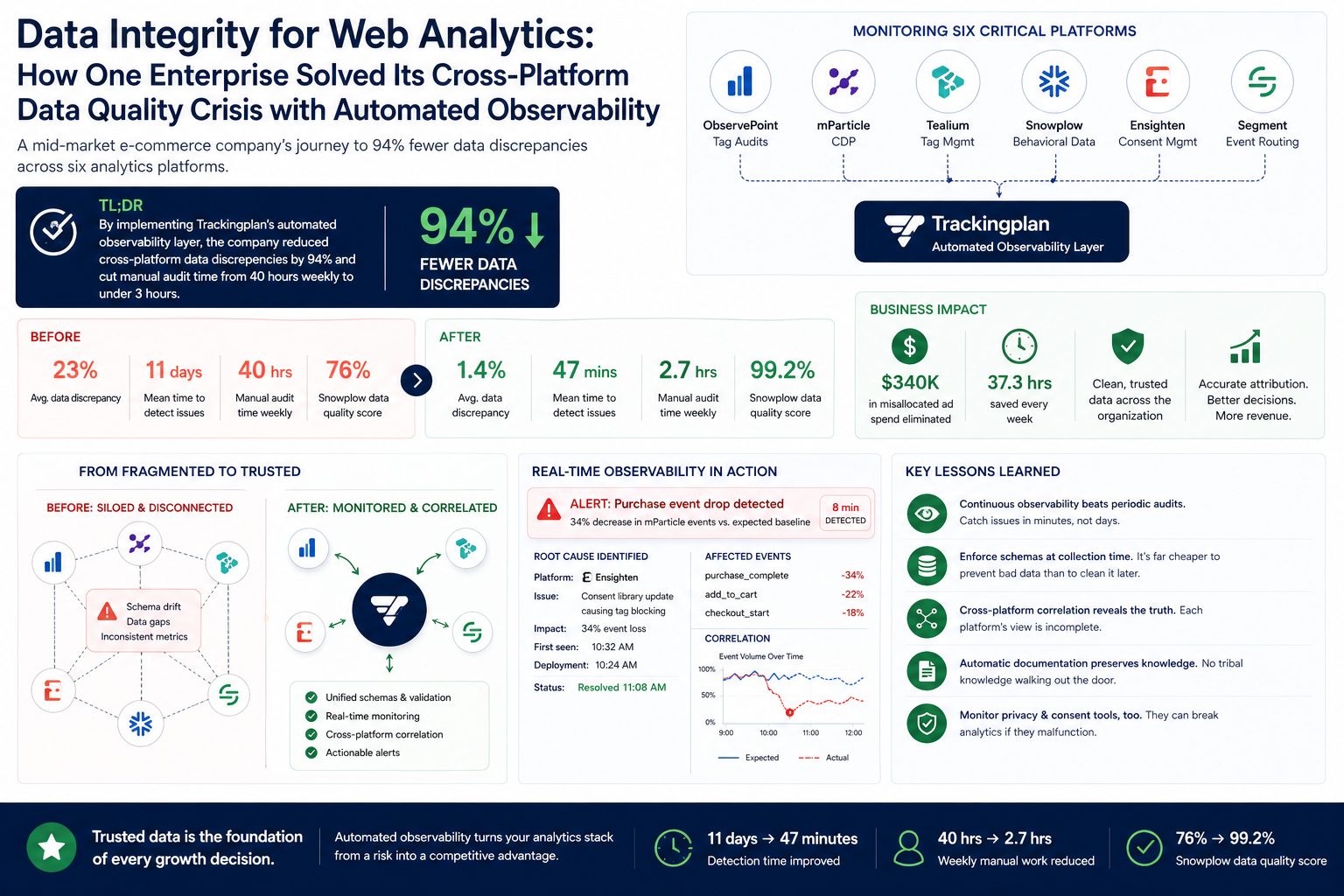
Why broken tracking is a revenue problem, not an IT problem
Before comparing tools, it helps to size the problem, because the cost of bad analytics data shows up on the P&L, not just in a dashboard.
Key statistics on tracking data quality
- The Macro Cost of Bad Data: Poor data quality costs organizations an average of $12.9 million per year, according to Gartner’s foundational data research (Magic Quadrant for Data Quality Solutions).
- Media Spend Waste: In marketing specifically, a Forrester Consulting study found that 21 cents of every media dollar were wasted due to poor data quality, and 26% of campaigns were directly degraded by tracking errors.
- Direct Revenue Attrition: The MIT Sloan Management Review, alongside Cork University Business School, estimates that enterprises lose 15 to 25% of their annual revenue to poor data quality.
- Strategic Paralysis: A Dun & Bradstreet and Forrester industry survey revealed that only 50% of B2B marketing and sales decisions are backed by data; the remaining 50% revert to pure intuition because go-to-market teams lack trust in their underlying reporting infrastructure.
The mechanism is specific and familiar to anyone who runs paid media. When a tag silently breaks or fires twice, platform-reported ROAS drifts away from reality. You scale campaigns that look like winners, pause ones that were actually working, and feed corrupted conversion signals back to ad platform algorithms — which then optimize toward the wrong audiences. The damage compounds daily until someone notices the report "fell off a cliff," often weeks later.
That lag is the core issue every approach below is trying to solve. The difference between them is how fast and how completely they catch the break.
The 5 Technical Approaches to Data Quality Assurance
1. Browser extensions (Manual Tag Inspectors & Session Debuggers)
TL;DR: Real-time inspection, in your browser, of the HTTP payloads fired on the page you're currently viewing. Provides hit-level detail, executed manually, one session at a time. Some extensions — like Analytics Debugger, Tag Assistant, and Dataslayer — also expose the full dataLayer push sequence, letting you see what data was pushed before the hit was sent. Others, like Omnibug, focus on decoding the outbound HTTP requests to analytics and ad platforms but do not surface the dataLayer directly.
Examples: Omnibug, Analytics Debugger, Google Analytics Tag Assistant.
What is a browser extension for web analytics?
A browser extension is a client-side developer tool that intercepts, parses, and displays HTTP data payloads transmitted from a user's browser to analytics and advertising servers in real time.
Core Mechanism
Browser extensions operate entirely within the local browser environment on a single-session, manual basis to inspect the dataLayer, tag firing sequences, and consent-mode flags of the specific URL string currently being rendered.
Pros
- Free or nearly free, zero setup, instant results.
- Maximum hit-level detail: you see the real payload, every parameter, consent-mode signals, the dataLayer, firing order.
- Irreplaceable for debugging during implementation and for verifying a specific fix.
Cons
- 100% manual; doesn't scale beyond the pages you personally click through.
- No history, no alerting, one browser/device/session.
- You only catch what you look at — there's no coverage guarantee. It's a point-in-time snapshot that depends on a human.
Primary Use Case: Frontend developers and digital analysts debugging individual conversion flows, performing spot-checks, or validating hotfixes in a local environment.
2. Site crawlers and scanners (Automated Synthetic Auditing)
TL;DR: Bots that simulate the user journeys you define, fire the tags, and validate them against rules. Some options also support dataLayer inspection: you can configure the tool to check for the presence and structure of dataLayer variables on audited pages, and set alerts if the dataLayer is missing or malformed. Automated and scheduled.
Examples: ObservePoint, DataTrue, Tag Inspector, Netvigie.
What is a site crawler in the context of analytics QA?
A site crawler is an automated script or headless browser bot that programmatically navigates through a website along predefined user pathways to trigger tags and validate payloads against static business rules.
Core Mechanism
These tools simulate user traffic on a scheduled or ad-hoc basis, evaluating the presence and execution of tracking scripts across staging, user acceptance testing (UAT), or production environments.
Pros
- Automated, repeatable, and scheduled; site-wide coverage of the paths you define.
- Rule-based validation and multi-environment support, so you can audit staging before you publish — a genuine pre-release QA gate.
- Strong for compliance audits: cookie inventories, PII leak detection, consent checks. Good for governance at scale and agency reporting.
Cons
- They only test the journeys you define — blind to new or unspecified paths and pages.
- Simulated traffic isn't real behavior: it misses logged-in states, dynamic content, and the real mix of devices, browsers, and edge cases.
- Many crawlers struggle with modern Single-Page Applications (SPAs), where navigation happens through client-side routing rather than traditional URL changes, making pages and events harder to discover automatically.
- Private or authenticated areas are often difficult to audit because crawlers must handle login flows, session management, multi-factor authentication, and other access restrictions.
- When crawlers do inspect the dataLayer, they only see it on the predefined journeys the bot executes—not across the full range of real user paths, application states, and interactions.
- High maintenance: every site change means updating the scripts and predefined user journeys.
- Enterprise pricing (DataTrue's Starter tier, for example, begins around $999/month) and still essentially provides only point-in-time validation between scheduled runs.
Primary Use Case: Pre-release QA gating within CI/CD deployment pipelines, automated privacy compliance audits, and regulatory cookie governance for enterprise domains.
3. API-based config auditors (Metadata & Property Governance)
TL;DR: Tools that connect via a read-only API to your GA4/GTM configuration and check it against best-practice checkpoints. Config layer, not hit layer.
Examples: GA4 Auditor, GAfix
What is an API-based config auditor?
An API-based config auditor is a server-to-server validation utility that connects directly to web analytics admin APIs to evaluate property settings, container variables, and configuration logic against deployment best practices.
Core Mechanism
Rather than observing data transmission in the browser, these utilities run diagnostic scripts against the metadata layer of platforms like GA4 or GTM to identify structural setup errors.
Pros
- Fast, cheap, no-code, and no site instrumentation required.
- Good coverage of the config layer: data retention, event naming, conversions, data streams, filters, PII settings. GAfix, for example, runs a structured checkpoint audit of both GA4 and GTM with read-only access.
- Ideal for standardized health checks and low-friction client reporting, GA4 Auditor's one-off report pricing suits periodic checks.
Cons
- They audit configuration, not collection. They can't tell you whether tags actually fire correctly for real users.
- No data layer visibility. They can't inspect or validate the data layer, making it impossible to detect issues before they reach GTM or analytics tools.
- Point-in-time snapshot, limited mostly to platforms with APIs (GA4/GTM). No validation of real hit payloads or cross-tool consistency.
- They don't provide reliable short-term monitoring or alerting because they rely on platform metadata and consolidated reporting, which can be delayed by data processing windows that often take up to 48 hours. As a result, they aren't suitable for detecting implementation issues as they occur.
Primary Use Case: Quick GA4/GTM config sanity checks, post-migration validation, and periodic standardized health checks of analytics properties.
4. Home-grown anomaly detection on BigQuery (Post-Hoc Data Warehouse QA)
TL;DR: Custom SQL or ML on your raw GA4 (or other) export to detect anomalies in the data you've already collected — volume drops, null parameters, cardinality shifts, conversion drift.
Examples: Custom SQL, dbt tests, BigQuery ML, Looker alerts.
What is BigQuery anomaly detection?
BigQuery anomaly detection refers to custom-built machine learning algorithms or scheduled SQL scripts executing within a cloud data warehouse to identify statistical variations, missing records, or schema shifts in raw analytics event data.
Core Mechanism
This is a reactive architecture that evaluates data after it has been collected, stored, and batch-processed, alerting teams to macroscopic deviations from standard data baselines.
Pros
- Fully tailored to your KPIs and business, it operates on the real collected data.
- No per-seat SaaS fee (just GCP compute), and it integrates with your existing stack and alerting.
- Total ownership, no vendor lock-in; catches downstream data-quality issues generic tools miss.
Cons
- Serious engineering effort to build and maintain. Needs data-engineering plus analytics expertise.
- Reactive by design: you detect the problem after the data lands, and the BigQuery export has latency — the collection window is already lost.
- Detecting absence is hard: a tag that never fires means rows that don't exist, and "what isn't there" is far harder to alert on than an anomaly in what is.
- Needs constant tuning to avoid alert fatigue, and GCP cost grows with volume.
- They often generate a high number of false positives, which can lead teams to ignore or deprioritize alerts over time, reducing their effectiveness in ongoing governance.
Primary Use Case: Mature data teams with BigQuery already in place seeking deeply tailored business-KPI threshold alerts and downstream pipeline validation.
5. Continuous data collectors / real-user monitoring (Proactive Edge Observability)
TL;DR: A lightweight collector observes the hits that real users' browsers actually send to every analytics and ad platform, in real time, models what "normal" looks like, and alerts on anomalies. Continuous, real traffic, hit-level.
Examples: Trackingplan
What is real-user monitoring (RUM) for web analytics?
Continuous real-user monitoring captures, parses, and analyzes the analytics and marketing requests generated by real users across live production traffic. Instead of replaying predefined user journeys or processing historical datasets, it builds a dynamic baseline of expected tracking behavior from actual traffic, validates events, parameters, destinations, and payload structures in real time, and automatically detects deviations, missing data, implementation changes, and data quality regressions as soon as they occur.
Core Mechanism
This is the category most directly aimed at the core problem above — catching breakage in production, fast, without you having to script journeys or wait for the warehouse. For agencies and enterprises that need reliable data in production, all the time, continuous real-user monitoring (RUM) is the most complete approach, because it watches the actual hits real users generate instead of a simulation, and flags breakage before it corrupts your dashboards.
Pros
- Real user traffic, not a simulation, so it catches the real-world edge cases crawlers never see. Trackingplan also captures and exposes the full dataLayer push sequence alongside each hit — across all real user sessions — making it possible to determine whether an issue originates in the tag manager or in the frontend data layer itself.
- Continuous and always-on, not point-in-time — it monitors tags as your actual customers trigger them.
- Coverage without defining journeys: it auto-discovers every vendor and tag and sees every hit that real users generate. Low maintenance, because there are no per-site scripts to update.
- Validates that events reaching GA4, Mixpanel, Amplitude, Segment, and others match your defined tracking plan, and alerts before corrupt data contaminates your dashboards.
- ML-based anomaly detection and alerting out of the box, covering both data quality and consent/privacy.
Cons — stated honestly
- It requires deploying a lightweight collector, and you're routing data through a third party, so security and privacy posture matter (evaluate certifications and data handling for any vendor here).
- It's the inverse of a crawler: it only observes what real users actually visit, so a page with no traffic isn't tested, and very low-volume events are statistically noisier for anomaly detection.
- Testing pre-release/staging is less natural than with a crawler.
Primary Use Case: Production monitoring at scale — agencies covering many client sites seeking to safeguard live production data, attribution accuracy, and ad-platform signal inputs, and enterprises protecting large ad budgets and attribution — where you need continuous coverage without maintaining journey scripts.
Comparison at a glance
| Approach |
Traffic |
Temporal Model |
Inspection Layer |
Maintenance |
dataLayer visibility |
Primary Strengths |
| Browser extensions |
You, manual |
Point-in-time |
Local Client-Side Hit |
None |
Yes (Analytics Debugger, Tag Assistant, Dataslayer); No (Omnibug) |
Deep-dive individual session debugging & validation |
| Crawlers and scanners |
Simulated (Synthetic / Bot) |
Scheduled |
Programmatic Pathway Hit (journeys) |
High |
Yes, but only for predefined user journeys and synthetic traffic. |
Pre-release QA, compliance |
| API config auditors |
N/A (config) |
Point-in-time |
Config (Property & Container Configuration) |
None |
No, they operate exclusively at the analytics property and configuration level. |
GA4/GTM config health checks |
| BigQuery Detection |
Production / Real |
Continuous (reactive) |
Downstream Warehouse Layer |
Very high |
No, they analyze data after it has been collected and processed. |
Custom KPI monitoring & business logic validation |
| Continuous monitoring (Trackingplan) |
Production / Real |
Continuous (proactive) |
Hit |
Low |
Yes, full dataLayer push sequence across 100% of real user sessions |
Live production observability, production monitoring at scale |
The gap that the first three leave — all of them either point-in-time or simulated — is exactly the one that matters most once you're live: what happens to the real data, all the time. That's why, for agencies and enterprises, continuous real-user monitoring tends to become the backbone rather than a nice-to-have. It's the only approach that assumes tracking will break (it always does, on the next release, the next consent change, the next third-party script) and is watching when it does.
Analytics QA Tools by Category
| Category |
Tools |
What they inspect |
| Browser extensions |
Analytics Debugger, Google Tag Assistant, Dataslayer, Omnibug |
Outbound hits and (for most) dataLayer pushes — manually, one session at a time |
| Site crawlers & scanners |
ObservePoint, DataTrue, Tag Inspector, Netvigie |
Tags, hits, cookies, and dataLayer variables — automatically, on predefined synthetic journeys |
| API config auditors |
GA4 Auditor, GAfix |
GA4 property settings and GTM container configuration — no hit or dataLayer inspection |
| Data warehouse anomaly detection |
Custom SQL, dbt, BigQuery ML, Looker |
Collected event data in the warehouse — reactive, post-collection only |
| Continuous real-user monitoring |
Trackingplan |
Hits, dataLayer pushes, pixels, and consent signals — continuously, across 100% of real production traffic |
The tools referenced in this article map to five distinct categories. Each category addresses a different layer of the data quality problem — no single tool covers all of them.
Which Framework Should Your Organization Deploy?
These approaches aren't mutually exclusive — they cover different moments in the data lifecycle, and a mature stack usually uses several:
- A browser extension while a developer implements and debugs.
- A crawler or API auditor acts as a gate before you publish.
- A continuous collector for always-on monitoring of real production traffic.
- BigQuery for the handful of business-specific anomalies that no generic layer captures.
The ROI case for agencies and enterprises
You can build the ROI argument straight from the numbers above, without hand-waving. If poor data quality wastes roughly a fifth of media spend (Forrester/Marketing Evolution) and typical enterprises lose millions a year to it (Gartner), then the relevant question isn't "can we afford continuous monitoring?" — it's "how much are we already losing during the weeks between a break and the moment someone notices?"
For Digital Performance Agencies
- Churn Mitigation: Continuous data monitoring means you catch client tracking failures within minutes, removing the catastrophic agency liability of discovering broken conversion pixels weeks late when client reports show a drop off a cliff.
- Operational Efficiency: Shifting from manual QA tasks to automated systems converts manual engineering hours into high-margin strategy execution. For instance, partner agencies using Trackingplan report an average 90% reduction in manual tracking-issue discovery time, saving dozens of hours per month per client.
- New Service Revenues: Continuous data quality tracking easily bundles into a premium, monthly "Data Governance and SLA Assurance" retainer.
All in all, that protects retention, turns data governance into a recurring, billable service line, and removes the "dedicated tag-QA person manually re-running audits" cost that crawlers impose.
For Enterprise Advertisers
- Ad-Spend Optimization: Automated data QA ensures that machine-learning optimization algorithms (such as Google Ads Smart Bidding or Meta Advantage+) are fed clean conversion signals, directly suppressing customer acquisition cost (CAC) inflation caused by broken event streams. Enterprise implementations of automated edge validation regularly protect multi-million-dollar budgets, ensuring that up to 21% of media spend isn't wasted on misattributed or missing conversion signals.
- Regulatory Compliance Assurance: Continuous monitoring acts as a real-time compliance checker, immediately alerting security teams if PII leaks into analytics hits or if tags execute in violation of user-selected consent string frameworks.
The value here is protecting large ad budgets and attribution from silent corruption, plus governance and consent monitoring at a scale where manual and simulated methods simply can't keep up.
The Bottom Line
The evolution of web analytics architecture in 2026 demonstrates that point-in-time audits are no longer sufficient to guarantee data integrity. Safeguarding digital ad spend and eliminating silent ROAS degradation at scale requires automated, continuous edge observability.
While organizations must evaluate vendors based on their specific security frameworks and pipeline requirements, platforms operating within the Continuous Data Collection paradigm —such as Trackingplan— provide continuous validation of production data using real user traffic. These solutions automatically detect anomalies and implementation issues, reducing the need for manual validation for teams seeking to eliminate silent ROAS killers and protect digital ad spend at scale.
Frequently Asked Questions
What is the best tool to keep web analytics accurate?
There's no single best tool; the choice depends entirely on the stage of the data lifecycle. If you're trying to debug a single page manually, browser extensions like Omnibug or Analytics Debugger can be enough and are usually the fastest option.
For checking GA4/GTM configuration, an API auditor like GA4 Auditor or GAfix. For pre-release QA and compliance, a crawler like ObservePoint or DataTrue. For continuous production monitoring of real user traffic, continuous data collectors such as Trackingplan provide the necessary always-on coverage.
What is the difference between a site crawler and real-user monitoring?
A site crawler and a real-user monitoring (RUM) tool both validate analytics tracking, but they operate on fundamentally different traffic and at different points in the data lifecycle.
A site crawler sends automated bots through predefined user journeys on your site — simulating clicks, page loads, and form submissions — and validates whether the expected tags fire correctly along those paths. The traffic is synthetic: no real user is involved. This makes crawlers excellent for pre-release QA and compliance audits, because you can run them against staging environments before anything goes live. The limitation is coverage: crawlers only see what you script them to see. Logged-in states, dynamic content, unusual device and browser combinations, and any journey you didn't define are invisible to them.
Real-user monitoring works the opposite way. Instead of simulating traffic, it intercepts the actual analytics and marketing requests that real users' browsers generate as they navigate your site in production. Coverage is automatic and complete — every tag, pixel, and dataLayer push that any real user triggers is captured, without you having to define journeys or write scripts. Because it operates on live production traffic, it catches edge cases, post-release regressions, and consent-driven variations that synthetic crawlers structurally cannot reach.
The practical consequence is that the two tools catch different classes of breakage. A crawler tells you whether your main conversion funnel works correctly in a controlled test. Real-user monitoring tells you whether it is working correctly right now, for all the users actually on your site — including the ones on obscure device configurations, behind consent banners, or hitting pages your crawler never visited.
What is the technical difference between a tracking audit and tracking monitoring?
A tracking audit is a point-in-time check of an account configuration or site snapshot: it tells you whether your setup is correct right now. Conversely, tracking monitoring is an uninterrupted, continuous process: it watches real hits as users generate them and alerts you the moment something breaks. Audits answer "is this correct today?"; monitoring answers "is this still correct, right now, and will I know before the data is corrupted?"
Why isn't a site crawler enough on its own for production data QA?
Site crawlers rely on synthetic user simulation and pre-mapped journeys, so they're blind to new pages and to real-world conditions like logged-in sessions and unusual device/browser combinations. It's excellent as a pre-release gate, and they tell you if your main funnel works for a bot, but they cannot verify if your tracking plan works across 100% of real-user edge cases.
Can't I just build anomaly detection on BigQuery myself?
You can, and mature data teams do — it's powerful and fully customizable. The trade-offs are heavy engineering and maintenance, and that it's reactive: you detect problems only after the data has landed and the export has run, so the collection window is already lost. It also struggles to detect missing data, since absent tags mean absent rows.
How much does bad tracking data actually cost businesses?
Studies put it high: industry baselines indicate that poor data quality costs enterprises an average of $12.9 million annually per organization (Gartner), 21 cents of every media dollar wasted in marketing (Forrester/Marketing Evolution), and 15–25% of revenue lost to poor data quality (MIT Sloan / Cork University). The financial loss occurs when broken or duplicated conversion signals distort ROAS, which leads teams to scale losers and pause winners.
Sources referenced: Gartner, Magic Quadrant for Data Quality Solutions (2020); Forrester Consulting for Marketing Evolution, "Why Marketers Can't Ignore Data Quality" (2019); MIT Sloan Management Review with Cork University Business School; Dun & Bradstreet and Forrester. Vendor and product details (ObservePoint, DataTrue, GA4 Auditor, GAfix, Trackingplan) reflect publicly available information as of 2026.