

Explore what an agentic analytics platform is and how it automates insights. Learn its core capabilities, use cases, and how to implement one for your business.
Your dashboard says conversions are down. Marketing thinks it's a campaign problem. Product suspects a broken checkout step. Engineering asks for reproducible evidence. The analytics team opens three tools, exports two CSVs, checks a tag manager, and starts a Slack thread that keeps growing.
That situation is why so many teams are looking past dashboards and toward a different model. They don't just need reports. They need a system that can watch data continuously, spot what changed, explain why it changed, and help the right people act before the issue spreads into wasted spend, bad reporting, or customer friction.
An Agentic Analytics Platform is the clearest expression of that shift. It changes analytics from a passive layer that waits for questions into an operational system that supports decisions in motion. For analysts, that means fewer repetitive investigations. For marketers, it means faster reaction to broken attribution, traffic anomalies, and campaign drift. For developers, it means better signal around data quality issues before those issues corrupt downstream tools.
What Is an Agentic Analytics Platform
Many organizations still run analytics like a help desk. Someone notices a problem, asks a question, waits for an analyst, gets a chart, asks a follow-up, and then waits again. That model breaks down when data moves constantly and business teams need answers during the working day, not after a reporting cycle.
An Agentic Analytics Platform changes that operating model. It doesn't just answer a prompt. It works toward a goal.
According to Trackingplan's overview of agentic analytics, agentic analytics shifts analytics from a static reporting layer into an active, autonomous decision engine that proactively monitors data, reasons through anomalies, and executes next steps without waiting for human input. That capability rests on three pillars: goal-directed behavior, interaction with databases and APIs, and adaptive reasoning based on intermediate findings.
If you want a second plain-English explainer, this guide on agentic analytics explained is useful because it helps separate the idea from the usual AI buzzwords.
The simplest mental model
Think of traditional analytics as a library. The books are there, but someone has to know what to look for, find the right shelf, read the material, and decide what matters.
An agentic system is closer to an operations desk. It watches incoming signals, compares them against goals and rules, investigates unusual changes, and routes the next action. Sometimes that action is a recommendation. Sometimes it's an alert. In approved scenarios, it can trigger a workflow.
That's the part people often miss. “Agentic” doesn't mean “chat with your BI tool.” It means the system can take a business objective like protect conversion tracking, reduce campaign waste, or detect broken event flows, then carry out multi-step analysis without needing a human to guide every click.
Why this matters to cross-functional teams
The impact isn't only technical.
- Analysts get relief from repetitive root-cause work.
- Marketers get earlier warning when tracking breaks or attribution starts drifting.
- Developers get clearer signals about implementation issues, schema mismatches, and unexpected event changes.
- Leaders get less lag between issue detection and action.
An agentic platform is useful only when it helps a team move from “something looks off” to “here's what changed and what to do next” without manual handoffs at every step.
That's why the category matters. It's not just another analytics interface. It's a new way to run the loop from observation to action.
How Agentic Analytics Differs from Traditional BI
Most business intelligence tools are built to help humans inspect data. They can be excellent at that. Tableau, Power BI, Looker, and similar tools organize information, visualize trends, and support reporting workflows. But they still assume a human is driving.
An Agentic Analytics Platform works more like a self-driving system than cruise control. Cruise control can maintain speed. A self-driving system handles more of the route, responds to conditions, and adjusts in real time. Traditional BI helps you look at the road. Agentic analytics helps traverse it.
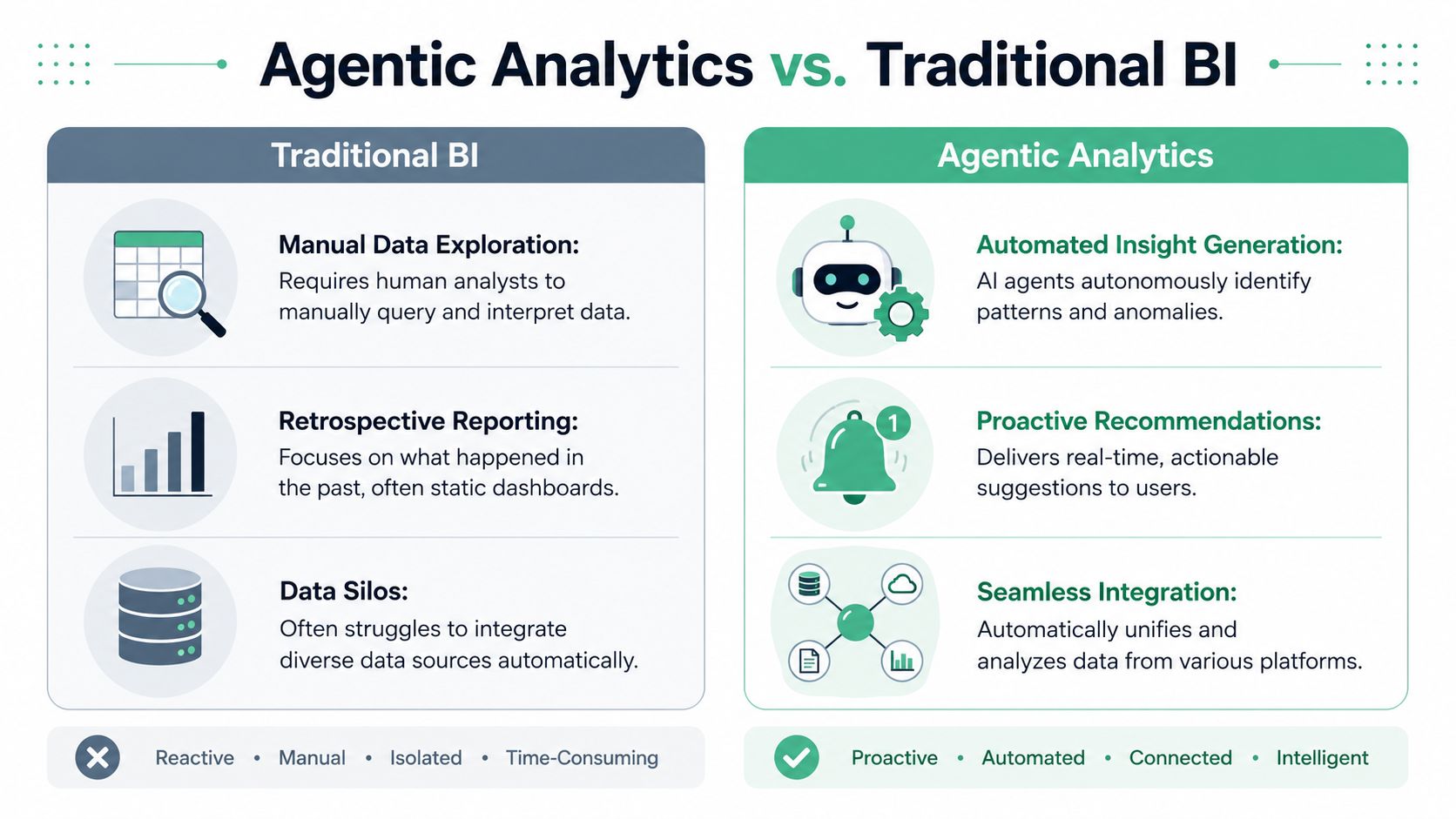
Siteimprove describes the shift clearly in its write-up on traditional business intelligence versus agentic analytics: agentic platforms deploy autonomous AI agents that independently reason over enterprise data, execute multi-step analytical workflows, and deliver answers with minimal human intervention, turning analytics from a passive reporting layer into a proactive decision engine that operates in real time.
Side-by-side comparison
| Dimension | Traditional BI | Agentic analytics |
|---|---|---|
| Primary mode | Human-led exploration | Goal-led autonomous investigation |
| Typical output | Dashboard, report, chart | Insight, explanation, recommendation, and sometimes action |
| Speed of follow-up | Depends on analyst availability | Continuous or near-real-time within system rules |
| Handling anomalies | User notices and investigates | System detects, reasons, and surfaces likely causes |
| Workflow scope | Often one query or one dashboard at a time | Multi-step reasoning across tools and datasets |
| Operational role | Reporting and retrospective analysis | Ongoing decision support |
Why this difference matters in practice
A traditional BI workflow often looks like this:
- A marketer sees weaker performance.
- An analyst checks campaign dashboards.
- Someone notices a data gap.
- Engineering investigates implementation.
- Days later, the team learns a pixel or event changed.
An agentic workflow compresses that sequence. The system monitors the data flow, identifies the anomaly, checks connected context, and routes the issue sooner. That's especially relevant in environments where analytics quality directly affects campaign optimization and measurement.
Teams working in marketing should pay attention to how this intersects with AI-driven execution. Trackingplan's article on agentic AI in marketing is a good reference for that operational angle.
Traditional BI tells you what happened. Agentic analytics is designed to notice what's happening, interpret the change, and help decide what happens next.
That doesn't make dashboards obsolete. It changes their role. Dashboards remain useful surfaces. They're just no longer the whole system.
Understanding the Core Capabilities
The phrase “agentic analytics” can sound vague until you break the platform into working parts. Under the hood, a production-ready system needs structure, context, orchestration, governance, and an interface people can practically use.
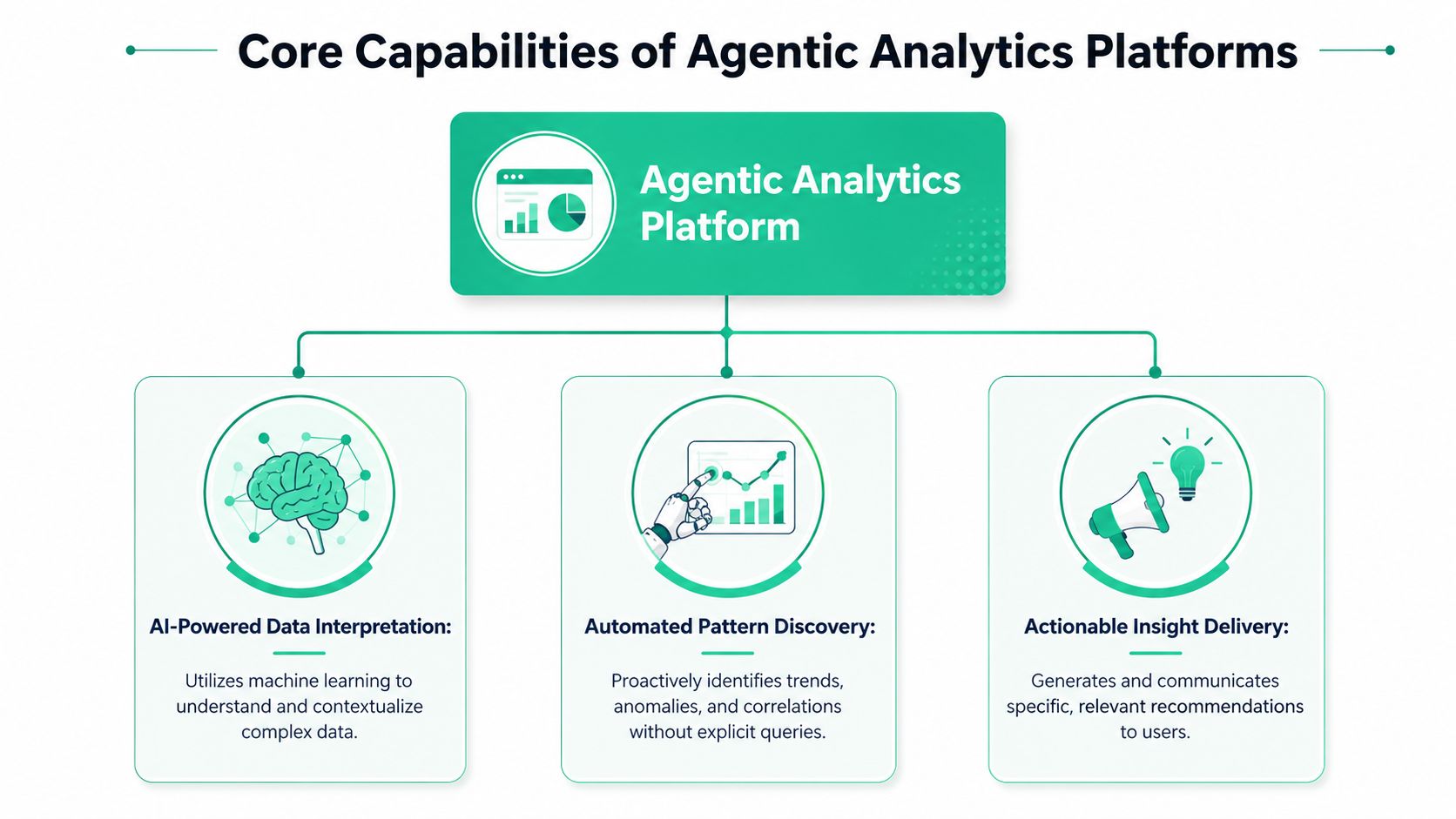
Promethium outlines the architecture in its guide to building an agentic analytics platform. It identifies five integrated components: federated data access, unified context management, multi-agent orchestration, explainable AI governance, and agent-native interfaces. It also describes the operating loop as Sense, Analyze, Explain, Recommend, and Act.
What those capabilities actually mean
Federated access and context
The platform has to reach the right data without creating confusion about meaning. If customer behavior lives in one system, CRM history in another, and campaign data elsewhere, the agent needs a coherent way to work across them.
Just as important, it needs semantic context. “Revenue,” “qualified lead,” or “conversion” can mean different things to finance, growth, and product. Without shared definitions, an agent may move quickly but still be wrong.
The operating loop in real life
The five-step loop becomes more concrete when you map it to a common incident:
- Sense pulls event streams, analytics payloads, API outputs, and warehouse data.
- Analyze detects a drop or mismatch.
- Explain identifies the likely source, such as a schema change or missing parameter.
- Recommend proposes the next best step, like pausing a budget rule or fixing an event mapping.
- Act triggers the approved workflow.
That's where observability becomes central. If the incoming data is unstable, undocumented, or inconsistent across tools, the loop starts with noise.
Practical rule: autonomy amplifies whatever foundation you give it. Clean, governed data produces useful action. Messy instrumentation produces fast confusion.
Orchestration and governance
A mature platform isn't one giant model doing everything. It usually coordinates specialized agents or services. One may monitor signals. Another may handle root-cause analysis. Another may manage workflow execution.
Governance is what keeps this safe. The platform needs clear access controls, auditability, and explainability so people can understand why it reached a conclusion and whether it should act on it.
Interfaces for non-technical teams
Natural language matters, but it's only one piece. The better interface is one that lets marketers, analysts, and developers meet the same issue from different angles. A marketer may want “what changed in paid social tracking today?” A developer may want the exact property mismatch. An analyst may want business impact and historical context.
In practice, these systems also benefit from reliable external context pipelines. If your agents need to pull structured information from the web or connected systems for retrieval workflows, tools like a Web Scraping API for RAG can fit that supporting role.
Agentic Analytics in Action Practical Use Cases
Monday morning. Paid media looks weaker, revenue is wobbling, and three teams are asking the same question in different words: did performance change, or did measurement break?

That tension is where agentic analytics becomes practical. A dashboard can show that something changed. An agentic system goes further. It checks the signal, tests likely causes, connects the issue to the right workflow, and gives each team the context they need to respond.
Tellius describes this well in its article on agentic analytics and autonomous action. The platform does not stop at surfacing insight. It can route the next step through actions such as creating support tickets, updating CRM records, adjusting operational settings, or alerting stakeholders before teams spend a day debating what happened.
A marketer trying to protect campaign spend
A performance marketer sees acquisition quality drop and has to decide whether to pause spend, change targeting, or wait. In a traditional setup, that decision is slow because the answer sits across several systems. Ads manager shows traffic, the product team checks landing page behavior, and analytics investigates whether a conversion event changed.
An agentic platform works like an air traffic controller for measurement. It watches the flow continuously, spots that paid traffic is still arriving, detects that a downstream event no longer matches the expected schema, and points to the likely break, such as a missing parameter or pixel issue. Then it sends the alert to the marketer and the implementation owner with the evidence attached.
The practical benefit is simple. Marketers stop wasting budget while teams argue over whether the problem is audience quality, site friction, or broken tracking.
That same operational pattern shows up in agentic AI for marketing operations, where the value comes from shortening the time between anomaly, diagnosis, and action.
A data quality analyst facing noisy implementations
For analytics QA teams, small errors are often the most expensive because they look believable. A renamed property, an event firing twice, or a consent rule blocking only part of the traffic can distort reporting for days before anyone notices.
Agentic analytics changes that job from reactive auditing to active monitoring. Instead of waiting for someone to report a strange dashboard trend, the system compares live behavior against expected tracking patterns, flags the anomaly, estimates where the issue started, and records the affected tools or destinations.
That matters for cross-team collaboration. Analysts get the business impact. Developers get the implementation detail. Marketing gets a clear answer on whether campaign decisions should pause or continue.
An e-commerce team handling revenue-impacting friction
An e-commerce team notices a familiar pattern. Product page views look normal. Add-to-cart events look normal too. Purchases fall anyway.
Without an agentic layer, each team forms its own theory. Product suspects checkout friction. Marketing suspects low-intent traffic. Engineering sees no major release and assumes the system is stable. Hours disappear in status checks, screenshots, and dashboard comparisons.
An agentic platform examines the path end to end. It compares current checkout behavior to the expected instrumentation map, checks whether server-side forwarding is still working, and identifies whether the problem is customer behavior or measurement quality. If the issue is a tracking break, it can open a ticket, alert the channel owner, and mark affected reports so no one optimizes against corrupted numbers.
That is the operational shift. Reporting used to describe problems after the fact. Agentic analytics helps teams contain the problem while it is still happening.
A growth and engineering team sharing the same incident
The strongest use cases appear where handoffs usually fail.
Growth teams care about spend, conversion rate, and experiment velocity. Engineers care about releases, event payloads, and system changes. Agentic analytics gives both groups a shared incident record. It is the same way a good bug tracker gives support and engineering one source of truth, except here the trigger is a data issue with business consequences.
That shared record reduces a common source of friction. Teams no longer need to spend the first meeting deciding whether the issue is real. They can start with the evidence, the likely cause, and the next action.
A Phased Approach to Adopting Agentic Analytics
Teams shouldn't start by asking, “How do we automate decisions?” They should start by asking, “Can we trust the data and the guardrails enough to let a system act on it?”
That's why adoption works best as a progression, not a leap.
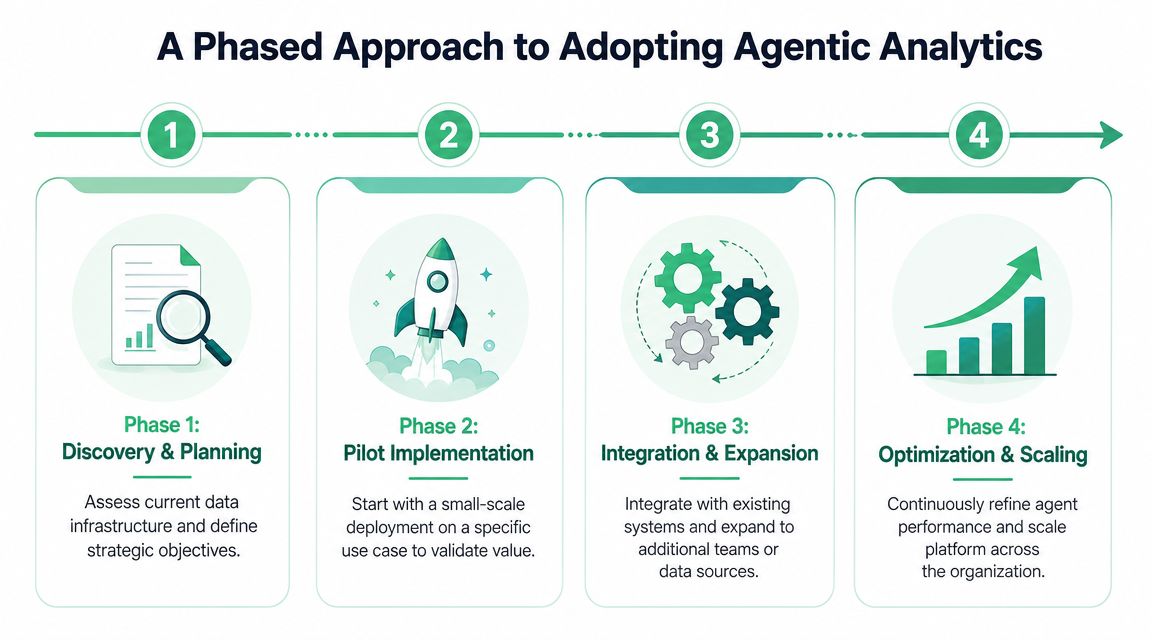
AtScale's glossary entry on agentic analytics adoption adds an important implementation detail: a Human-in-the-Loop first phase, where people approve recommendations, can reduce initial agent logic validation errors by 40-60% before teams move into controlled autonomy.
Phase 1 with discovery and trust building
Start narrow. Pick one recurring problem where delay is painful and the workflow is clear.
Good starting points include:
- Data pipeline monitoring: recurring checks for anomalies and likely root causes
- Marketing performance diagnostics: campaign issues tied to event-level behavior
- Analytics QA: broken pixels, schema mismatches, missing events, or consent-related issues
At this stage, the goal isn't automation for its own sake. It's trust. Teams need to document key business definitions, identify authoritative data sources, and agree on what “normal” versus “actionable” looks like.
Phase 2 with assistive recommendations
Now the platform can begin sensing changes and generating recommendations, but humans still approve the next step.
That approval loop matters for two reasons:
- It validates whether the system's reasoning matches business reality.
- It reveals where your semantics, data lineage, or access rules are still weak.
“Start with a use case where the team already knows the cost of delay. That makes both evaluation and trust much easier.”
Phase 3 with controlled autonomy
Once the recommendations prove reliable, you can let the system act in low-risk workflows. That may include routing alerts, creating tickets, updating records, or triggering bounded operational rules.
Keep the autonomy scoped. Campaign budget moves, CRM updates, and workflow routing need different tolerance levels than reporting notifications. The system should act only where business constraints are explicit.
What has to be in place before this step
| Requirement | Why it matters |
|---|---|
| Clear semantic definitions | Agents need shared meaning for metrics and entities |
| Governed access controls | Agents must respect the same permissions as users |
| Observability | Teams need to detect drift and unexpected behavior |
| Documented workflows | Approved actions need clear boundaries |
Phase 4 with expansion and optimization
After one successful use case, expand sideways, not everywhere at once. Add adjacent teams that benefit from the same data foundation. Refine agent logic based on what the earlier phase surfaced. Watch for drift. Keep auditability strong.
Cross-team collaboration is indispensable. Analysts define business meaning. Marketers define acceptable action ranges. Developers define instrumentation reality and system constraints. Without that shared model, an agent can automate the wrong thing very efficiently.
Choosing a Platform and Measuring Success
Platform selection gets messy when every vendor promises speed, intelligence, and automation. The safer approach is to ignore slogans and inspect operating discipline.
One issue stands out. OvalEdge notes in its review of agentic analytics tools and compliance concerns that 73% of CISOs in a 2025 Gartner survey flagged AI agent opacity as a top compliance risk. That makes explainability and auditability more than nice-to-have features.
What to look for during evaluation
Use a short checklist:
- Explainability: Can the platform show how it reached a conclusion?
- Replay capability: Can teams inspect what happened after an agent took or recommended an action?
- Semantic grounding: Does it understand your approved business definitions?
- Access governance: Does it respect role-based permissions consistently?
- Observability: Can you detect drift, degraded outputs, or unstable behavior?
- Workflow integration: Can it route actions into tools your teams already use?
A platform that can't answer those questions clearly will create work, not remove it.
How to measure success without vague ROI language
Avoid vanity metrics. Measure whether the platform improves operational response and decision quality in the workflows you care about.
A practical scorecard might include:
- Incident response speed: Are data issues identified and escalated faster?
- Resolution quality: Do teams get better root-cause context on the first pass?
- Optimization velocity: Can marketers adjust campaigns sooner because measurement issues surface earlier?
- Analyst efficiency: Are repetitive investigations declining?
- Governance confidence: Can compliance, analytics, and engineering review agent behavior without guesswork?
If your current pain is unstable tracking and unreliable downstream reporting, strong data quality monitoring is part of that evaluation, not a side issue. An agent can only be as useful as the data it's allowed to trust.
If a vendor demonstrates a slick interface but can't explain audit trails, permissioning, and drift visibility, you're looking at a demo, not an enterprise operating system.
Begin Your Journey to Autonomous Analytics
Monday morning. Marketing sees a drop in conversions, analytics sees a reporting anomaly, and engineering is asked whether anything changed in the tracking setup. By the time each team compares notes, hours are gone and decisions are already being made on shaky numbers. Autonomous analytics changes that operating model. It helps teams detect issues earlier, understand likely causes faster, and route the right next step to the right owner.
The practical starting point is not maximum automation. It is a reliable foundation. Agentic systems only make good decisions when the underlying signals are accurate, observable, and shared across teams in a way everyone can trust.
That is why the first milestone is operational clarity.
For analysts, that means fewer repetitive investigations into whether a metric moved because the business changed or because instrumentation broke. For marketers, it means catching tracking gaps before campaign performance is judged on incomplete data. For developers, it means seeing what changed across web, app, server-side, and destination pipelines without digging through scattered logs and tickets.
A useful way to frame it is this: dashboards tell you what happened. An agentic analytics platform helps your organization respond while the issue is still small. But that only works when data quality monitoring, change detection, governance, and team workflows are connected. Otherwise, automation speeds up confusion.
If your current process still depends on manual QA, brittle tests, and reactive debugging, start there. Fix the bottleneck closest to trust. Once teams can spot data quality issues early and trace changes back to a source with confidence, automated analysis and action become much more realistic.
If you want to see what that looks like in practice, review product demos or recorded walkthroughs from vendors in your category and look closely at how they handle monitoring, alerting, and analytics QA in real workflows.
If you're building toward autonomous analytics, start with the foundation that makes agent actions trustworthy. Trackingplan helps teams monitor analytics implementations, detect data quality issues in real time, and give marketers, analysts, and developers a shared view of what changed before bad data turns into bad decisions.







