

Discover agentic analytics: the next leap beyond BI. Autonomous AI agents deliver real-time insights. Data observability is critical.
The biggest risk in agentic analytics isn't that the agents will be too weak. It's that they'll be confident on bad inputs.
That concern sounds less exciting than autonomous insights and real-time decisions, but it's the point that matters most in production. 73% of enterprise analytics failures stem from data quality issues, according to the Gartner figure cited by Domo's market guide on agentic analytics, and that same source notes that major vendors don't document automated root-cause analysis for agent-driven errors (Domo summary of Gartner market guide). If an agent pauses a campaign, escalates a pricing issue, or flags churn risk from flawed tracking, the problem isn't theoretical. Teams act on it.
That's why the future of BI won't be decided only by better models or slicker interfaces. It will be decided by whether teams can trust the behavioral data, event streams, schemas, and business definitions those agents rely on. Agentic analytics changes the shape of work. Observability and analytics QA determine whether that change is useful or dangerous.
What Is Agentic Analytics and Why It Matters Now
Passive dashboards are starting to look like a transitional technology.
For years, most organizations accepted the same operating model. Data gets collected, transformed, loaded into a warehouse, turned into dashboards, and then interpreted by analysts or business users who decide what to do next. That process still works for reporting. It doesn't work well when the business needs continuous monitoring, immediate interpretation, and fast action.
Agentic analytics shifts analytics from a static reporting layer into an active decision engine. Hex describes it as a transformation in depth of insight, breadth of reach, and speed of insight, moving beyond traditional BI and search tools toward autonomous action that improves decisions for both business and technical teams (Hex on agentic analytics).
What makes this different isn't just natural language querying. It's autonomy. The system doesn't wait for someone to open a dashboard, notice a change, ask a follow-up question, and manually coordinate the response. It can monitor, reason, explain, recommend, and in some cases trigger the next step inside the workflow itself.
Why the timing matters
Two forces are converging.
First, AI systems have become capable of handling more than one prompt-response exchange. They can reason across multiple steps, use tools, evaluate intermediate results, and keep working toward a goal. Second, teams are tired of the gap between “we saw something in the dashboard” and “we changed the outcome.”
That gap shows up everywhere. Marketers spot a conversion drop too late. Product teams miss a broken event until a weekly review. Revenue teams see a performance shift but need several people to investigate before anyone acts.
Practical rule: If insight still depends on someone noticing a chart at the right time, your analytics stack is reactive.
Agentic analytics matters now because it aims to close that delay. It brings analysis closer to operations, where decisions happen. For marketing teams thinking about this evolution in execution-heavy environments, agentic AI in marketing is a useful lens because campaign systems are one of the clearest places where insight and action need to stay connected.
What changes for teams
Analysts don't disappear. Developers don't hand the keys to a black box. Marketers don't stop making decisions.
What changes is the default mode of analytics. Instead of waiting for people to pull answers from data, systems start pushing relevant findings, likely causes, and next actions back to the teams that own the outcome. That's the key shift. Not smarter dashboards. Less dashboard dependence.
Traditional BI vs Agentic Analytics
Traditional BI is a road map. Agentic analytics is a live GPS.
A road map helps you understand the terrain. A GPS keeps checking conditions, reroutes around problems, and tells you what to do next. That's the difference in practice. Traditional BI supports human-led exploration of historical information. Agentic analytics supports continuous, goal-directed investigation that can keep moving without a user driving every click.
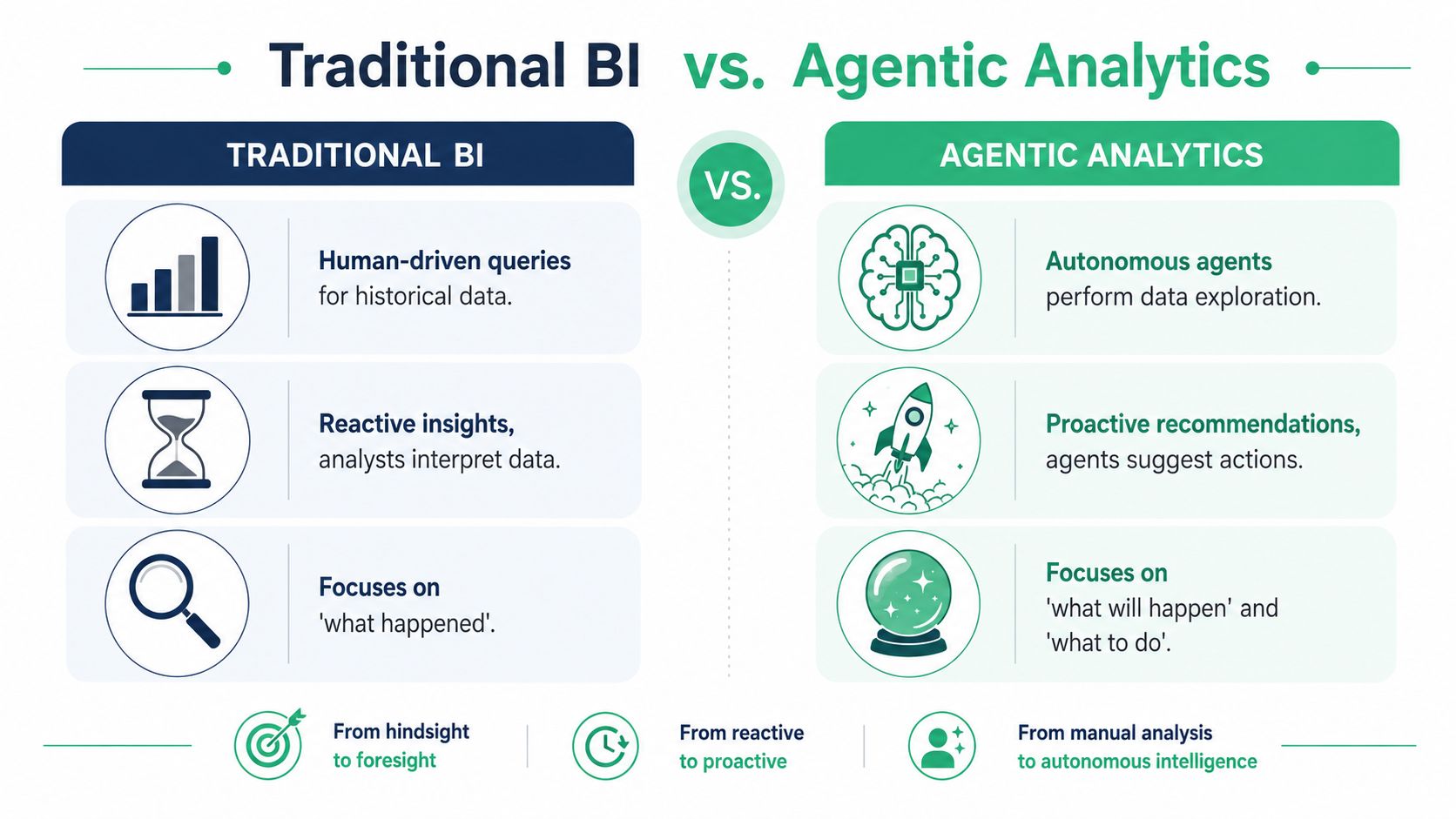
Scoop's definition gets to the heart of it. Unlike chatbots or copilots that answer single questions, agentic systems plan and execute complex, multi-step investigations independently, from data ingestion through final reporting. Scoop also frames the “agentic” quality around three capabilities: goal-directed behavior, environmental interaction with systems like databases and APIs, and adaptive reasoning based on intermediate findings (Scoop Analytics on agentic analytics).
Side-by-side comparison
| Dimension | Traditional BI | Agentic analytics |
|---|---|---|
| Primary mode | Human-driven reporting and exploration | Autonomous investigation and action support |
| Typical trigger | Someone opens a dashboard or asks a query | A goal, threshold, anomaly, or workflow condition |
| Data interaction | Mostly manual filtering, slicing, and follow-up analysis | Continuous access to data sources, tools, and context |
| Output | Charts, reports, dashboards | Findings, explanations, recommendations, and downstream actions |
| Question style | “What happened?” | “What's happening, why, and what should happen next?” |
| Pace | Periodic and reactive | Ongoing and proactive |
| User burden | High. Users must interpret and coordinate next steps | Lower for routine decisions, with escalation where needed |
What works better in each model
Traditional BI still wins in several situations:
- Executive reporting: Board decks, monthly reviews, and audited KPI snapshots still need stable presentation layers.
- Exploratory analysis: Analysts often want to test hypotheses manually before operationalizing anything.
- Shared visibility: Dashboards remain useful as communication artifacts across teams.
Agentic analytics wins when delay itself is the problem:
- Always-on monitoring: Conversion funnels, product events, attribution feeds, and operational metrics don't wait for business hours.
- Multi-step diagnosis: Agents can inspect upstream tables, compare segments, check metadata, and assemble a narrative faster than a fragmented manual workflow.
- Operational execution: Some findings need a recommendation or trigger, not another chart.
Static BI tells you where the problem is. Agentic analytics can keep investigating after the first clue.
For teams evaluating where their current stack falls short, this guide to key features for analytics platforms in 2026 is useful because the evaluation criteria are shifting from visualization features toward reliability, responsiveness, and actionability.
The practical trade-off
The leap in capability comes with a harder requirement. A dashboard can be wrong and still get challenged by a human before anyone acts. An agent can be wrong and move faster than your review process.
That's why agentic analytics shouldn't be treated as a shiny BI upgrade. It's a different operating model with a different risk profile.
Core Architecture and Key Components
Agentic analytics succeeds or fails at the architecture layer. The interface gets the attention, but the outcome depends on whether the system can reason over trusted metrics, use the right tools, and prove that its actions are based on valid data.
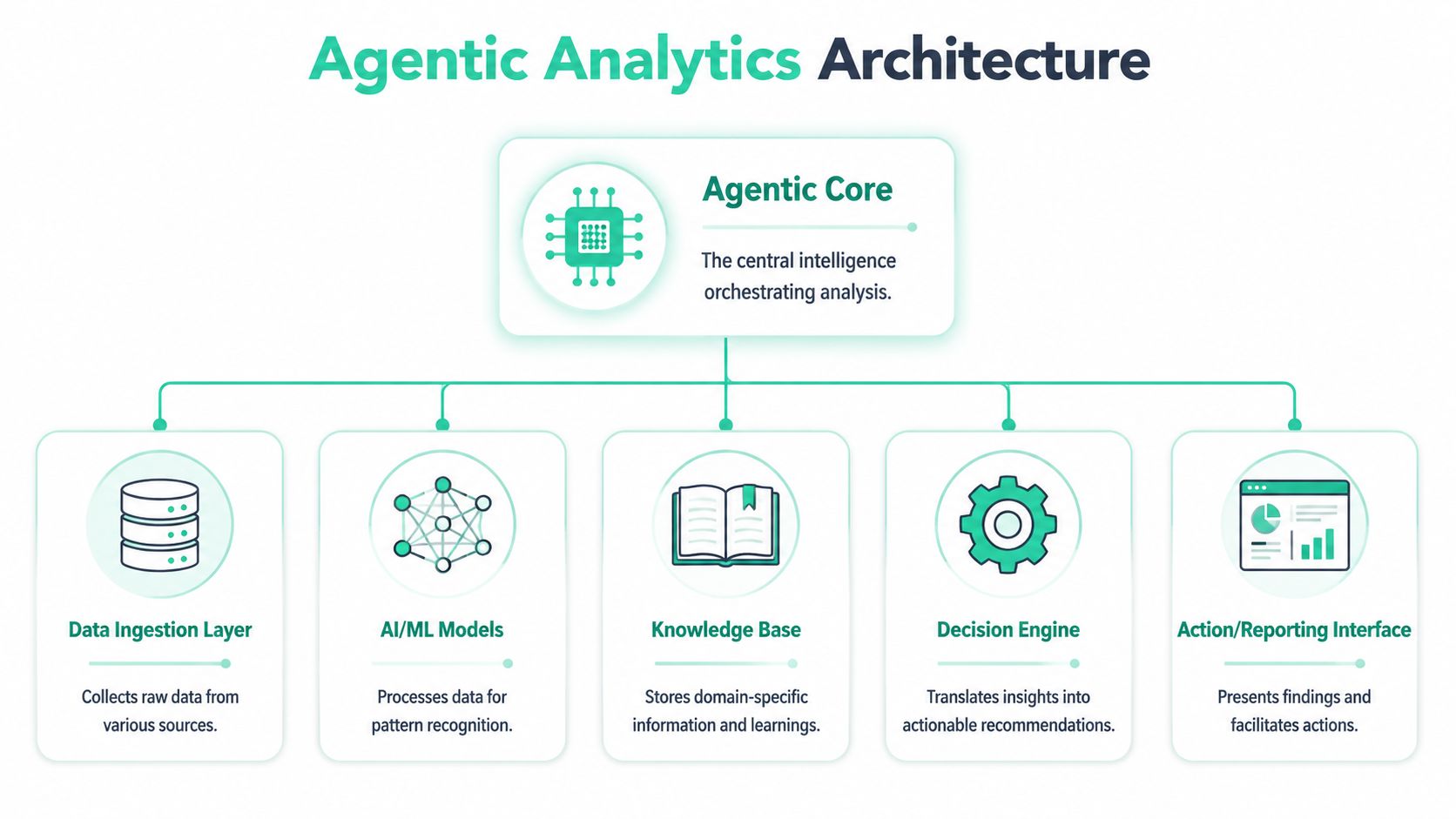
OvalEdge outlines six critical pillars for enterprise agentic analytics: a semantic query layer, multi-agent orchestration, retrieval mechanisms for data access, tool-use capabilities for computation, human-in-the-loop review for high-stakes decisions, and automated alerts for anomaly detection (OvalEdge on enterprise agentic analytics). That model is useful because it reflects how production systems break. Failures usually come from weak context, weak controls, or weak monitoring, not from the language model alone.
The stack that actually matters
A working setup usually includes five layers.
Semantic layer and business context
Agents need a stable definition of the business before they can answer anything well. If “revenue,” “active user,” or “qualified lead” changes across teams or tables, the agent will return answers that sound polished and still be wrong.
The semantic layer maps business language to metrics, dimensions, entities, and rules. It also limits improvisation. That matters because an agent should not invent a SQL interpretation for a KPI that finance and marketing define differently.
Orchestration and planning
This layer decides how the system works through a task.
An orchestrator turns a prompt or trigger into a sequence of steps, selects tools, evaluates intermediate results, and decides whether to continue, ask for review, or stop. In practice, this is the difference between a chatbot that responds once and an agent that can investigate a drop in conversions across several systems.
Retrieval and tool use
Useful agents need access to warehouse tables, event streams, APIs, metadata, lineage, documentation, and governance rules. Retrieval gets the right context into scope. Tool use executes the next step, whether that means running a query, validating a schema, checking an attribution feed, or opening a ticket.
For teams redesigning analyst workflows around these capabilities, this guide to AI task automation for analysts is a practical reference because it connects automation patterns to work analysts already do every week.
Decision policy and human review
Autonomy without policy creates avoidable risk.
Every agentic system needs thresholds for what it can do on its own, what requires confirmation, and what should only produce a recommendation. A sensible policy might allow an agent to summarize a traffic anomaly automatically, while requiring approval before changing budget allocations, suppressing campaigns, or updating downstream systems.
Observability and analytics QA
This layer gets underestimated, then becomes the reason projects stall in production.
An agent can only act safely if the team can verify event quality, schema stability, source freshness, and output behavior. If a naming change, dropped parameter, or broken tag looks like a real business shift, the system will investigate the wrong problem and may recommend the wrong fix. Observability needs to sit inside the architecture, alongside planning and retrieval, because the agent has to distinguish product behavior from instrumentation failure.
A practical operating loop
Most agentic systems follow a repeatable loop even if vendors label it differently.
Collect inputs
The system pulls from databases, APIs, event streams, metadata, and business rules. Freshness and source reliability matter here because stale inputs produce fast, confident mistakes.Analyze and investigate
The agent looks for changes, compares segments, checks related signals, and follows the next question raised by the data.Explain the finding
Output needs more than a result. Teams need a readable account of what changed, where the change showed up, and which inputs shaped the conclusion.Recommend or execute
The system proposes an action or takes one, based on policy. Low-risk cases may trigger an alert or create a task. Higher-risk cases should pause for review.
Where architecture usually fails
The common failure points are predictable.
- Context gaps: Agents can reach tables but cannot tell which sources are governed, current, or trusted for decision-making.
- Access design problems: Permissions built for human analysts often create either blocked workflows or overly broad agent access.
- Disconnected anomaly handling: Teams detect an issue, but the alert does not connect to root-cause checks, instrumentation validation, or remediation.
- No production QA loop: Outputs are generated, yet nobody checks whether the underlying tracking changed, whether the recommendation quality drifted, or whether the agent acted on broken inputs.
That last point is why real-time anomaly detection for analytics pipelines belongs in the core design, not as an afterthought in a monitoring dashboard. In practice, agentic analytics requires the same discipline as any production data product. Teams need observability on the inputs, QA on the instrumentation, and review paths for the actions. Without that foundation, the architecture looks advanced on paper and behaves unpredictably in production.
Practical Use Cases Across Business Functions
Agentic analytics matters when teams need to move from detection to response before the opportunity or failure has already passed.

The practical question is simple. Where does analysis repeatedly stall because people have to chase context, validate inputs, and coordinate across teams? Those are the places where agentic systems can save time, if the underlying instrumentation is trustworthy and teams can verify what changed.
Marketing and growth
Marketing teams feel the delay first. Paid social efficiency drops, branded search weakens, or conversion rate falls on a key landing page. In a traditional workflow, channel managers check platform dashboards, analysts compare sessions and conversion events, and someone has to confirm whether the issue is real demand, audience fatigue, site friction, or broken tracking.
An agent can compress that triage cycle. It can compare campaign cohorts, inspect landing page behavior, flag a sudden change in event volume, and route the result correctly. Sometimes the answer is budget reallocation. Sometimes the right action is to stop and validate tracking before anyone touches spend.
That distinction matters more than the automation itself. Fast action on bad analytics data is expensive.
Teams that invest in data observability for analytics systems give agents a better chance of making useful recommendations because they can separate performance changes from measurement failures.
Ecommerce and operations
Ecommerce teams operate across demand, margin, fulfillment, and customer experience at the same time. A dashboard can show that carts are down. It usually cannot explain whether the cause is pricing, shipping estimates, stock visibility, promo logic, or a frontend event that stopped firing after a release.
An agent can monitor those signals together and produce a clearer first diagnosis. If product page engagement is steady but add-to-cart events fall sharply after a deployment, the issue may sit in instrumentation or UX. If traffic quality changes and checkout completion drops only for a campaign segment, the problem may be acquisition mix. If inventory and fulfillment data are connected, the same system can flag products that look healthy in demand reports but are heading toward stockout or delivery-delay problems.
For smaller teams that are still strengthening the basics of data operations, this practical guide to big data analytics for SMBs is useful because it connects ambitious analytics goals with operational reality.
Product and engineering
Product and engineering teams often lose time in the gap between a vague symptom and a reproducible issue. Users abandon a flow. Support tickets rise. Conversion slips on one browser version. The hard part is assembling enough evidence to decide whether the problem belongs to UX, application logic, release quality, or data collection.
Agentic analytics can reduce that assembly work. The system can watch event streams, compare cohorts by device or app version, identify where abandonment increases, and package the evidence into a ticket or incident summary. That shortens time to investigation.
It also creates a new dependency. If event definitions drift, schemas change subtly, or client-side tracking breaks after a release, the generated diagnosis can point engineering to the wrong place. In practice, the best product use cases are not the flashy ones. They are the repetitive triage tasks where good instrumentation and QA already exist.
Finance and leadership
Finance and executive teams need faster interpretation, not just faster reporting. Revenue quality changes, pipeline conversion softens, CAC rises in one segment, or a regional performance dip starts affecting forecast confidence. Static BI can show the variance. It rarely gives decision-makers a usable explanation without follow-up work from analytics and operations.
An agent can assemble that first layer of interpretation by tracing which business units, channels, or customer segments moved, then summarizing what deserves immediate review. Leaders still make the call. The value is that they start from a clearer problem statement, with supporting context, instead of waiting for several teams to build the narrative by hand.
Across functions, the strongest use cases share the same pattern. The win comes from faster triage, clearer root-cause hypotheses, and better coordination. Those benefits hold only when teams can trust the data feeding the system.
The Unspoken Prerequisite Analytics QA and Observability
Most writing about agentic analytics skips the part that determines whether it works safely in production. It assumes the agents will operate on trusted data. That assumption is where many deployments go wrong.
![]()
If an autonomous system is allowed to reason over behavioral data, campaign signals, product events, and attribution feeds, then analytics QA and observability become a control layer, not a nice-to-have. The Domo summary of Gartner's market guide makes this plain: 73% of enterprise analytics failures stem from data quality issues, and it highlights that major vendors don't document automated root-cause analysis for agent-driven errors. The same source points to schema mismatches and missing pixels as exactly the kinds of failures that can trigger false actions, such as pausing ad campaigns because the anomaly is fabricated rather than real (Gartner figure cited by Domo).
That's the unglamorous truth. A smart agent on broken data doesn't become approximately right. It becomes efficiently wrong.
Why classic data quality checks aren't enough
Most analytics teams already have some quality controls. dbt tests, warehouse monitoring, tag audits, dashboard checks, and manual QA all help. They're still not enough for agentic systems.
The problem is timing and granularity. Traditional checks often happen after data lands, after reports refresh, or after someone notices something odd. Agentic analytics shortens the time between input and action, so the validation layer also has to move closer to real time.
The dangerous failures are often quiet:
- Schema drift: An event still arrives, but a property changes shape or naming.
- Missing events: A purchase fires in one flow but disappears in another.
- Pixel failures: Paid media platforms stop receiving the signals they depend on.
- PII leakage: Sensitive values get passed into analytics or marketing destinations unintentionally.
- Consent misconfiguration: Tags fire in ways that don't match the actual consent state.
Any one of those can distort an agent's interpretation. The more automated the action layer becomes, the less tolerance you have for silent data breakage.
Field note: If your team finds analytics issues through dashboard oddities or campaign underperformance, your observability layer is too late for agentic workflows.
What observability needs to cover
A credible observability setup for agentic analytics should answer four questions continuously:
| Question | Why it matters |
|---|---|
| Did the event fire? | Missing behavioral signals can make normal business activity look like a performance collapse. |
| Did it fire correctly? | Property mismatches and malformed payloads change interpretation without throwing obvious errors. |
| Did it reach the right destinations? | Attribution, ad optimization, and downstream reporting break when pixels or connectors fail. |
| Did anything sensitive leak? | Privacy and governance failures are operational risks, not just compliance issues. |
Analytics QA becomes more than a pre-launch checklist. It becomes an always-on verification layer across web, app, and server-side instrumentation.
Why this gap matters more in 2026
The same Domo summary frames this as a critical risk for teams deploying agentic systems in 2026, specifically because vendors focus on trusted data as a premise without covering how to detect agent-facing failures in real time (agentic analytics risk context). That future-facing warning matters because the next wave of deployments won't fail only on model quality. They'll fail on instrumentation reliability, semantic drift, and undetected data breakage.
To understand the discipline behind that safety net, this explanation of what data observability is is worth reviewing. It helps clarify why monitoring data pipelines alone doesn't solve the analytics QA problem.
A practical example is easier to grasp in video than in abstraction:
Trackingplan's YouTube channel also has additional demonstrations that are useful for teams trying to understand how schema mismatches, missing pixels, and implementation issues surface in real workflows. Those examples matter because observability is rarely persuasive until people see how mundane the failure modes are.
The operating principle that teams should adopt
Treat agentic analytics the way you'd treat production software with write access. You wouldn't let code deploy without testing, monitoring, permissions, and rollback paths. Autonomous analytics deserves the same seriousness.
That means:
- Validate upstream behavior: Don't assume event collection is stable because the dashboard still loads.
- Monitor implementation drift: Front-end releases, SDK changes, consent updates, and vendor tags can alter meaning without obvious breakage.
- Separate signal from instrumentation failure: Before an agent acts on an anomaly, the system should check whether the anomaly might be caused by tracking issues.
- Escalate high-stakes decisions: Human review still belongs where the cost of a false action is high.
Without that layer, teams won't have agentic analytics. They'll have automated confidence built on fragile telemetry.
Getting Started With Governance and Best Practices
The mistake often made is starting with the agent.
The better sequence is to start with readiness. Snowplow's guidance is especially useful here: for agentic analytics to work, teams must first validate that customer behavioral data is structured and high-quality enough for an agent to reason over directly, and they need three context layers in place: table usage metadata, semantic definitions, and business context (Snowplow on agentic analytics readiness).
A practical rollout path
Start with data trust
Before introducing autonomous reasoning, verify that your event model, naming conventions, and destination mappings are stable. At this stage, many organizations discover they have acceptable reporting quality but poor operational quality.
An agent doesn't just need data. It needs data it can interpret without guessing.
Build the context layer
If your warehouse is full of overloaded fields, duplicate metrics, and undocumented tables, don't expect strong results from natural language or autonomous workflows.
Create shared metric definitions. Document dataset relationships. Mark which tables are trusted for production decision-making. Give the system enough context to distinguish between a temporary scratch model and a business-critical source.
Strong governance for agentic analytics starts before the first prompt. It starts in the semantic and behavioral foundations.
Define action boundaries
Not every insight should trigger action. Some should generate alerts. Others should produce recommendations. A smaller subset should be allowed to change workflows automatically.
Set those boundaries early:
- Low-risk actions: Notifications, summaries, and issue creation
- Medium-risk actions: Suggested optimizations with human approval
- High-risk actions: Escalation-only paths with explicit review
Keep humans in the loop where the stakes justify it
Full autonomy sounds efficient until the action is expensive, irreversible, or visible to customers. Human review belongs in campaign pauses, pricing changes, customer communications, and anything touching privacy or compliance.
For leadership teams shaping those guardrails, resources on AI governance help bridge policy and operations. A practical example is how F1Group assists with AI governance, which is useful when you need a framework for oversight rather than another model demo.
What works in practice
The teams that get value early usually do three things well.
- They begin with a narrow use case such as anomaly triage, campaign monitoring, or product funnel diagnostics.
- They treat observability as a prerequisite rather than a cleanup step after deployment.
- They define ownership clearly across analysts, engineers, marketers, and governance stakeholders.
That operating model is less flashy than an all-in autonomous rollout. It's also the model that has the best chance of producing trusted results.
If you're preparing for agentic analytics, start with the commonly overlooked layer. Trackingplan helps data, marketing, and engineering teams monitor analytics implementations, detect schema mismatches and missing pixels, catch PII leaks, and keep behavioral data trustworthy before autonomous systems act on it.







