

Learn what is schema validation and why it's crucial for data integrity. Our guide covers examples, common errors, and tools for reliable analytics tracking.
A dashboard can look polished and still be wrong.
That usually becomes obvious at the worst moment. Paid media is live, revenue looks inflated in one report and undercounted in another, and the team starts blaming attribution, cookies, consent banners, or the analytics platform itself. Then someone inspects the raw event payloads and finds the actual issue: fields changed shape, required properties disappeared, or campaign parameters stopped following the agreed format.
That's the problem schema validation solves. It gives teams a way to check analytics data at the moment it is produced or ingested, instead of discovering errors after reports, audiences, and bidding decisions have already been affected. In Martech environments, that matters because most tracking is fire-and-forget. If a bad event slips through, you often can't recover it later with confidence.
What Is Schema Validation and Why Does It Matter
Schema validation is the process of checking whether data matches a defined structure before that data is trusted downstream. In analytics work, that means confirming that event names, dataLayer properties, parameter types, and campaign fields follow agreed rules every time they are sent.

A simple way to think about it is a blueprint. The schema defines what a valid event should look like. The validator checks the incoming payload against that blueprint. If price should be a number, currency should be a string, and product_id must always exist, the validator enforces those rules consistently.
The formal definition is straightforward. Training Camp's schema validation glossary describes it as verifying that data conforms to a defined structure and format, including analytics fields such as dataLayer properties, event parameters, and UTM tracking conventions. That's exactly why it matters in measurement programs. Small structural mistakes become business mistakes once they reach dashboards, audiences, or attribution models.
What breaks when there is no schema
Without validation, teams usually find errors too late. Common examples include:
- Missing required values like
transaction_idon a purchase event - Wrong data types such as sending
"10.99"as text instead of10.99as a number - Inconsistent naming where one team sends
add_to_cartand another sendsaddToCart - Broken campaign fields that stop UTM-based reporting from grouping traffic correctly
Those issues are especially common in a well-defined analytics data layer, because the data layer sits between implementation and reporting. If it's unstable, everything downstream inherits that instability.
Practical rule: If the business relies on a field for reporting, audience building, or attribution, that field needs a schema.
Why cross-functional teams should care
Analysts care because trusted reporting starts with trusted event structure. Developers care because vague telemetry bugs are expensive to debug. Marketers care because campaign optimization depends on consistent dimensions and clean conversion signals.
Schema validation gives all three groups a shared contract. It turns “bad data” from a vague complaint into a specific, testable failure with a clear fix.
How Schema Validation Works
Schema validation works like a strict bouncer checking a guest list. The data is the person at the door. The schema is the guest list with rules. The validator compares one against the other and decides whether the payload gets through, gets flagged, or gets routed for correction.
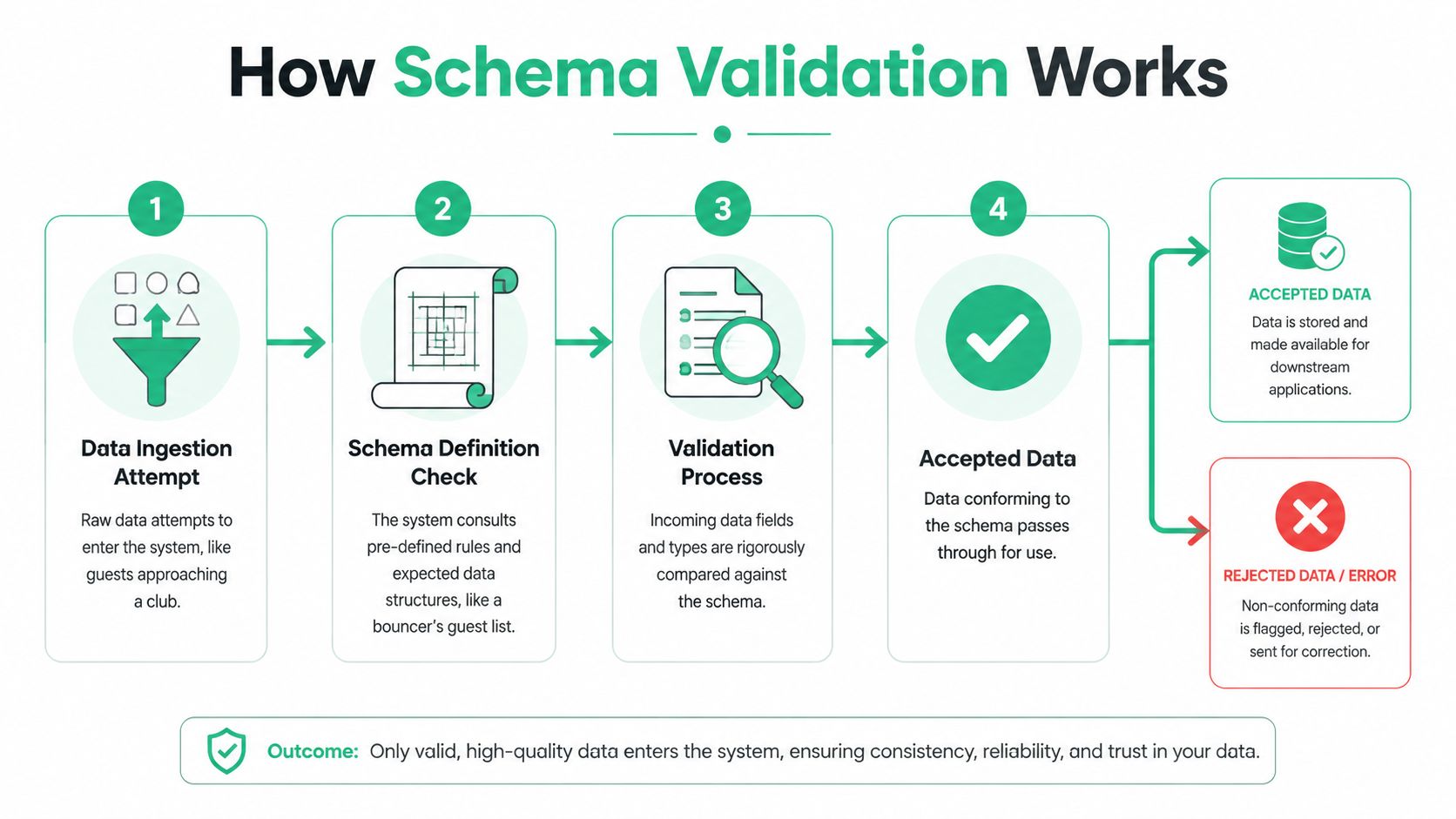
In analytics systems, that check usually happens around event collection, tag execution, pipeline ingestion, or warehouse loading. The important point is not the exact location. The important point is that the check happens before the data pollutes reporting undetected.
The three moving parts
Every validation flow has three core components:
The schema
This is the rule set. It defines allowed fields, types, required values, accepted formats, and sometimes conditional logic.The incoming payload
This is the event, object, or record being tested. In Martech, that might be apage_view,purchase, orsign_upevent from a browser, app, or server-side collector.The validator
This is the engine that compares payload to schema and returns either success or an explicit list of failures.
Packet Coders' explanation of schema validation captures the mechanics well: the schema acts as the blueprint, and any deviation in type, format, or structure triggers an error.
What the validator actually checks
A validator usually inspects several rule categories at once:
- Type checks like string, integer, number, or boolean
- Required fields such as
event_name,product_id, orcampaign - Format rules such as valid email, date, or URI structures
- Allowed values for fields that should only accept a known set
- Nested object rules when event properties contain structured sub-objects
Schema validation acts as a deterministic gatekeeper, enforcing strict adherence to predefined rules. When a record fails validation, the system flags the specific violation instead of causing unseen corruption in downstream analytics, preventing malformed records from skewing attribution metrics or triggering system failures.
A useful implementation pattern for analytics teams is to align those checks with the actual event design, not just generic JSON shape checks. That's where an analytics schema organized by event types becomes practical.
To see this in a product context, this video from Trackingplan's channel shows how teams approach validation and QA in real analytics implementations:
A validator is only useful if its error messages help someone fix the issue quickly.
Blocking versus non-blocking validation
In APIs, teams often block invalid requests. In analytics, that's not always the right choice.
Marketing telemetry is frequently asynchronous and business-critical. If you block all traffic on every mismatch, you may protect data quality but hurt site behavior or lose events entirely. That's why real-time analytics teams often prefer non-blocking validation at collection or observability layers. The event still gets flagged, alerts still fire, but user traffic isn't interrupted.
That trade-off is one reason generic API guidance often feels incomplete for Martech teams.
Common Schema Languages You Should Know
Once teams understand the logic of validation, the next question is which schema language fits their stack. The answer depends on where data originates and how it moves. For digital analytics and web-based data layers, JSON Schema is usually the first place to start. In older enterprise systems, XML Schema still appears. In high-volume event streaming, Avro and Protobuf are common.
Why JSON Schema gets most of the attention
JSON Schema is the most practical option for many analytics implementations because browsers, tag managers, APIs, server-side collectors, and modern event pipelines already work heavily with JSON.
The standard has also matured quickly. JSON Schema Draft 06 was released in September 2016, and Draft 2020-12 is the current standard, reflecting a 300% increase in schema complexity and validation rules. That growth matters because modern telemetry needs more than simple field presence checks. It often needs conditional rules, reusable definitions, and tighter constraints.
A useful companion for analytics teams working with GA4 conventions is this semantic data layer guide for GA4, because schema quality improves when naming and meaning are stable, not just data types.
Comparison of Common Schema Languages
| Language | Primary Use Case | Data Format | Key Strength |
|---|---|---|---|
| JSON Schema | Web apps, APIs, analytics events, data layers | JSON | Human-readable and well suited for validating event payloads and tracking structures |
| XML Schema (XSD) | Enterprise integrations and legacy systems | XML | Strong for strict document validation in older or regulated environments |
| Avro | Streaming pipelines and distributed data systems | Binary with schema definition | Efficient for data transport and schema evolution in event-heavy pipelines |
| Protobuf | Service-to-service communication and performance-sensitive systems | Binary | Compact serialization and strong compatibility for engineered back-end systems |
What matters more than the language
Teams sometimes spend too much time debating the format and too little time defining the contract. In practice, the harder problem is not whether you use JSON Schema or Avro. It's whether every team agrees on what user_id, price, campaign, or consent_status mean and how they must appear.
For Martech work, JSON Schema is often enough because it maps cleanly to dataLayer objects and event payloads. For warehouse or streaming environments, teams may keep JSON at the edge and use Avro or Protobuf deeper in the pipeline.
Choose the schema language that matches where your validation pain actually starts, not the one that looks most sophisticated on an architecture diagram.
Why Schema Validation Is Critical for Analytics and Marketing
Analytics errors rarely announce themselves. A campaign launches, conversions appear lower than expected, remarketing audiences shrink, or ROAS looks too good to be true. The root cause is often structural. A required field went missing. A numeric metric arrived as text. A naming convention drifted across teams.
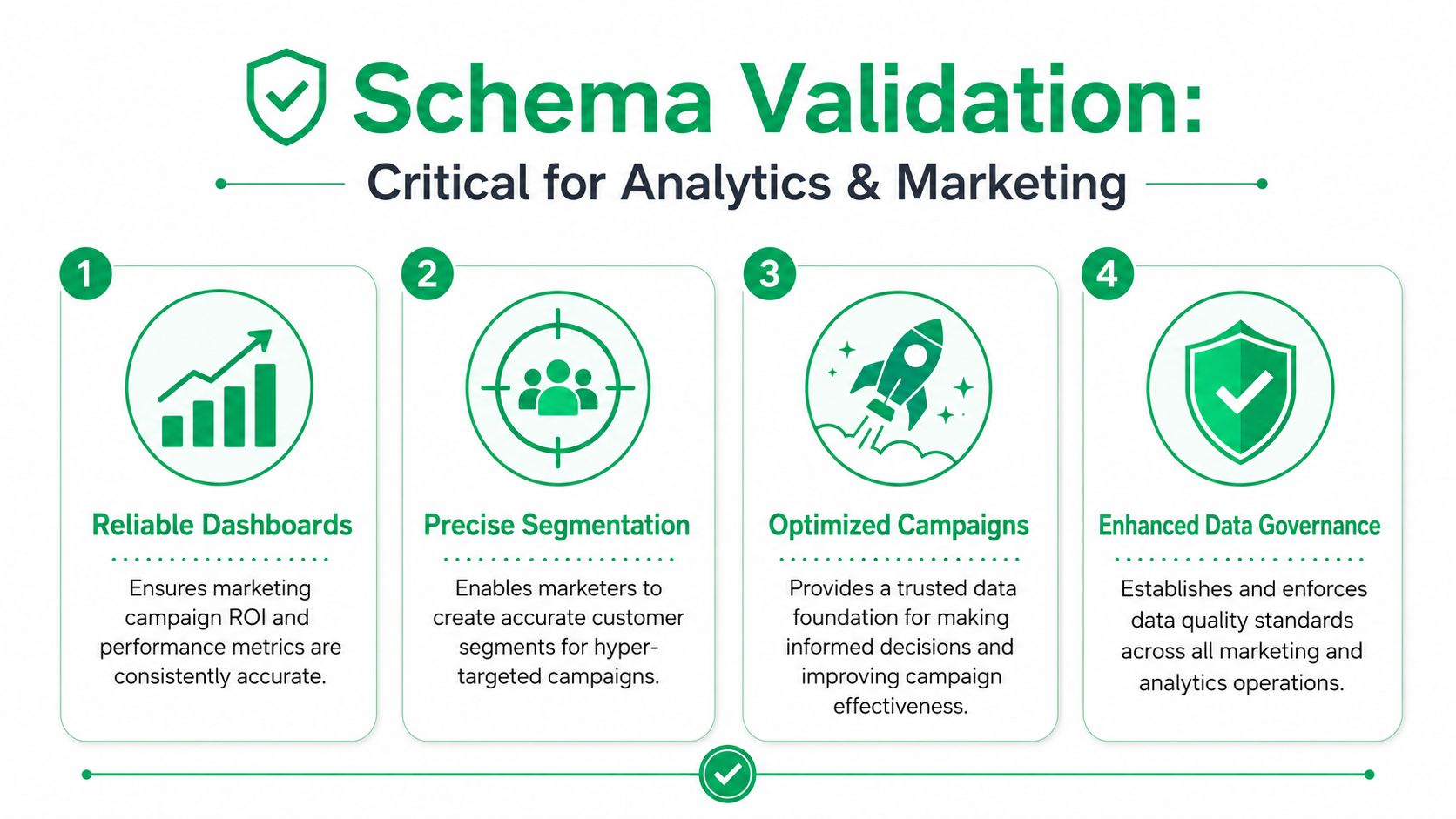
That's why schema validation matters more in marketing than generic technical guides usually admit. It doesn't just keep data tidy. It protects campaign decisions, budget allocation, and audience logic.
The tracking failures that hurt the most
The most damaging analytics issues are often simple:
- Revenue as the wrong type. If
revenueorpriceis sent as a string instead of a number, calculations and aggregations can break or behave inconsistently. - Missing event parameters. A purchase event without
transaction_idorcurrencycan distort attribution and reconciliation. - UTM drift. If campaign parameters don't follow agreed naming conventions, reports fragment into multiple near-duplicate dimensions.
- Pixel property mismatches. Ad platform pixels often expect specific field names and value types. A malformed payload can still fire while carrying unusable data.
Why automation changes the economics
Manual QA catches some of this, but it doesn't scale across web, app, and server-side implementations. Once there are many releases, many teams, and multiple destinations like Google Analytics, Adobe Analytics, Mixpanel, Segment, or Snowplow, reactive debugging becomes expensive.
Organizations that implemented automated schema validation saw a 92% reduction in data quality incidents, and teams in the Martech sector reduced manual audit time by 74%, leading to a 45% increase in ROI for data-driven marketing campaigns.
Those numbers matter because they describe a shift in operating model. Instead of waiting for analysts to discover broken reports, teams catch structural failures closer to the source.
Reliable dashboards start upstream
A dashboard doesn't become reliable in Looker, Tableau, or Power BI. It becomes reliable when the event contract is enforced before data gets there.
The strongest analytics programs treat validation as part of governance. That includes event definitions, naming conventions, consent expectations, and ownership across teams. A useful next step for teams working through that operating model is data governance for analytics.
When marketers say they want better dashboards, they usually mean they want fewer surprises. Schema validation is one of the few controls that directly reduces those surprises.
A Practical Schema Validation Workflow Example
The easiest way to understand schema validation is to look at a real event.
Assume an e-commerce team wants to validate an add_to_cart event before trusting it in reports. The team expects every event to include a product identifier, a numeric price, a currency code, and a quantity. That expectation becomes the schema.
Example schema
Below is a simple JSON Schema for that event:
{"$schema": "https://json-schema.org/draft/2020-12/schema","type": "object","required": ["event_name", "product_id", "price", "currency", "quantity"],"properties": {"event_name": { "type": "string", "const": "add_to_cart" },"product_id": { "type": "string" },"price": { "type": "number" },"currency": { "type": "string" },"quantity": { "type": "integer" }},"additionalProperties": false}This schema is intentionally strict. It doesn't just say “send something shaped like an event.” It says which fields must exist, what types they must use, and that extra undeclared fields aren't allowed.
Zuplo's guide to verifying JSON Schema is useful on this point. A validator checks both the schema and the data instance, and the more specific the schema is, the more useful the validation becomes.
A valid payload and an invalid one
A payload that should pass:
{"event_name": "add_to_cart","product_id": "SKU-12345","price": 29.99,"currency": "USD","quantity": 1}A payload that should fail:
{"event_name": "add_to_cart","product_id": "SKU-12345","price": "29.99","currency": "USD","quantity": 1}The problem is subtle. The price value looks correct to a human, but it is a string, not a number.
What a good validation error looks like
A useful validator shouldn't just reject the event. It should return an actionable message, such as:
pricemust be of typenumber. Receivedstring.
That's the practical value of validation. It shortens the path from detection to fix. Developers can locate the source quickly. Analysts don't need to reverse-engineer why revenue reports look inconsistent. QA teams can approve releases against explicit rules instead of visual spot checks.
Best practices here are simple and worth following closely:
- Be specific. Broad schemas let bad telemetry through.
- Use the correct draft via
$schema. That avoids inconsistent validator behavior. - Make errors descriptive. “Invalid payload” is not enough for debugging.
- Keep the schema close to the tracking plan. If definitions drift, validation loses value.
A small, strict schema like this can prevent hours of investigation later.
Common Errors and Reliable Telemetry Practices
Most schema validation failures fall into a few familiar categories. The pattern matters because once teams recognize the failure type, they can debug much faster and harden the implementation permanently.

The errors teams hit most often
Type mismatches
A value arrives in the wrong type, such as"true"instead oftrue, or"99.95"instead of99.95. This often comes from tag manager variables, DOM scraping, or inconsistent server formatting.Missing required properties
The event fires, but one field the business depends on isn't there. In practice, this often happens after front-end changes or partial rollouts.Unexpected extra fields
A payload includes unplanned properties that nobody documented. Sometimes that's harmless. Sometimes it signals rogue tracking, duplicate implementations, or leaking data that shouldn't be sent.Format failures
The field type is technically correct, but the content doesn't follow the expected format. Campaign identifiers, timestamps, emails, and URLs are common trouble spots.
Debugging habits that actually work
When a validation error appears, don't start in the dashboard. Start at the source event.
Inspect the raw payload first
Check what the browser, app, or server sent. Don't assume the tag manager preview or reporting UI tells the full story.Compare against the canonical schema
Teams lose time when they compare a payload to old documentation instead of the active rule set.Trace ownership
Find which team owns the field. A missingproduct_idusually belongs to implementation logic, not analytics configuration.Review recent releases
Many telemetry failures come from innocent front-end refactors, consent changes, or campaign setup changes.
Practices that make telemetry reliable
The best validation programs are boring in the right way. They remove ambiguity and reduce custom fixes.
Schemas should be specific and strict. The stronger the contract, the easier it is to catch mistakes early.
Use $ref to stay DRY. Reusable definitions prevent copy-paste drift and keep common property changes in one place.
Version schemas in Git. This creates a change history that analysts and developers can review together.
Validate in automation, not just manually. CI checks, pipeline checks, and runtime monitoring each catch different classes of failure.
One practical option in this category is Trackingplan, which monitors analytics implementations across web, app, and server-side stacks, detects schema and property mismatches, and alerts teams when issues appear in real time. It fits best as an observability layer, not as a replacement for having a clear schema in the first place.
One habit to keep: treat telemetry definitions like production code. Review them, version them, and test them before release.
There's also a privacy angle that teams shouldn't ignore. In marketing analytics, some “schema mismatches” are really privacy failures, such as unexpected email addresses or phone numbers appearing in fields that were never supposed to contain PII. Validation rules are stronger when they're paired with controls that detect those violations early.
Move From Reactive Fixes to Proactive Governance
When people ask what is schema validation, they often expect a technical definition. The better answer is operational. It's the discipline of making analytics data trustworthy before anyone builds a report, audience, or optimization decision on top of it.
That shift changes how teams work. Analysts stop spending so much time validating whether numbers can be trusted. Developers get clearer requirements and clearer failure messages. Marketers stop discovering implementation problems through campaign underperformance.
Schema validation also works best when it's shared. Engineering defines how events are emitted. Analytics defines what the business needs. Marketing and product teams help define the meaning of key fields and the consequences of getting them wrong. The schema becomes a contract between those groups.
If your current process depends on broken dashboards to reveal bad data, you're still operating reactively. A stricter, earlier validation layer is what moves the team toward proactive governance. That's where reliable reporting starts.
If you want a practical way to monitor analytics quality continuously, Trackingplan helps teams observe dataLayer changes, event mismatches, UTM issues, missing pixels, and other telemetry problems before they turn into unreliable dashboards.








